Last month I teased the three major updates we had released at that time. One of those updates was the new Antidote v0.4.0 platform, which was covered in the following blog post. In this post, I’d like to discuss another of those three updates, which was the migration of the NRE Labs production environment to a new infrastructure host.
Note that this blog post discusses the flagship deployment of the NRE Labs project, hosted at https://labs.networkreliability.engineering. This is meant to provide insight into how we run the site, and the infrastructure decisions we make to power the site. This isn’t the only way to run the NRE Labs curriculum, and it’s certainly not the only way to use Antidote - this is just an informative blog to show what we’re doing for our use case.
NRE Labs Resource Considerations
A brief aside on NRE Labs’ computing requirements. We see on average, ~100 lessons launched a day. There are rarely more than a handful of concurrent lessons - they’re generally well spread out. That said, every once in a while we do see spikes in usage, and considering many of our lessons currently involve several copies of virtual network devices, it doesn’t take long to start using a large amount of RAM.
On the other hand, the underlying Antidote platform is fairly aggressive at cleaning up resources for inactive lessons, so in general, resource utilization tends to get smoothed out pretty evenly. This means that while we need a decent amount of RAM to support the “dips” that show up with a spurt of activity, there is a certain point where adding more RAM is mostly pointless.
However, the one thing we can never get enough of is speed. Ever since the project began, NRE Labs has been all about making decisions to keep the user experience interactive, and fast. We don’t want to sacrifice speed to maintain interactivity - we demand both. We want to provide the learner with a fully on-demand environment that they have full access to, and we want to give it to them as quickly as humanly possible. If someone heard in a meeting that they need to learn how to write a Python script to query a network device API, we want them to be able to do it by the end of that meeting.
History of NRE Labs
NRE Labs was starting to take shape in the summer of ‘18. We were building containers for lesson endpoints, and some of those containers were running VMs inside them (primarily for network operating systems). The Antidote platform was built to run not only on top of Kubernetes but also integrated with the Kubernetes API.
It was also around this time that we started to think about platforms on which to run NRE Labs. Our early prototyping had been done on Google Cloud to this point, for one main reason - GCE has configuration options for nested virtualization. This was necessary for us because we were running VMs (network devices) within VMs (GCE instances) and without these extensions, the performance was……bad. So, we stuck with GCP for the time being. It seemed to work well, and GCP as a whole also had a lot of extra services like load balancing, security, monitoring, etc.
NRE Labs was officially launched in October of 2018, and we spent the next few months making improvements to the curriculum, the underlying platform, and continuing to get more experience with GCP and the operational tooling we built on top. In these months, we learned two important lessons:
- Managing performance is hard - Hardware acceleration can only improve nested virtualization to a point. At the end of the day you’re still dealing with a fairly significant performance penalty, and the reality is that most network operating systems weren’t even designed for a single layer of virtualization - much less two. In addition, the idea of running any compute-sensitive workloads in a cloud means you’re subjected to the noisy-neighbor problem. Most applications get around this by scaling out, which is an option we don’t have. Each lesson spins up a single container for each lesson endpoint and needs to boot quickly, otherwise, we lose the attention of the learner.
- Most cloud providers’ instance types optimize for quantity, not speed - Cloud VMs are often highly optimized for RAM or number of CPU cores. It’s very rare to have an instance type with a reasonably fast core speed, and even when they exist, they’re usually a TON of RAM or cores, way too many.
So, we started looking for alternative solutions that sat in the sweet spot of all of these:
- The performance of bare-metal (no “outer” virtualization layer)
- 100% API-driven provisioning and management, just like any leading cloud provider
- Compute package(s) optimized for our needs - enough RAM and cores to live on, but fast core speed.
Selecting Packet To Run Our Cluster
It didn’t take us long to discover Packet, as they basically fit all three of the requirements above, and to my knowledge, Packet is the only one out there that does all three particularly well.
As an example, there are - of course - plenty of providers that will give you bare-metal, but the management plane isn’t very programmable. Similarly, I am aware AWS (and others) are starting to have more bare-metal offerings, but these are often MASSIVE servers - well beyond what we’re looking for on a per-node basis.
Obviously, Packet does the bare-metal part (that’s their whole thing) so here are the two aspects to Packet that really sealed the deal for me:
- Simple, API-Driven Management Plane - One of the biggest draws to cloud infrastructure is the ability to provision and control infrastructure programmatically via APIs and everything that enables, such as the usage of infrastructure-as-code (IaC) tools like Terraform. We didn’t want to lose this ability when moving to our new provider. Fortunately, Packet not only offers a fully-featured API to work with their service, they also maintain their own Terraform provider. Since we were already heavily using Terraform, seeing that Packet maintained their own provider made the switch a lot easier.
- Ideally-Sized Compute Platforms - Packet has a variety of compute options, but the one that we are currently going for is c1.small which currently clocks in at 4 cores at 3.5GHz, and 32GB RAM, with a 120GB SSD. This is objectively smaller than the instances we were previously getting with GCP, but the performance was sized to exactly what we needed.
There was never really a moment when we decided we wanted to go live on Packet. Since it was easy enough to get started, we just spun up a few servers and started running Antidote with the NRE Labs curriculum. We had this on a separate subdomain for a while to do some extensive testing, and then one day we just switched the DNS over to our Packet cluster.
Stepping Out Of The Umbrella
This may all sound like the move was rainbows and unicorns. While we’re pretty happy with the new infrastructure, it wasn’t without its hurdles. As my friend Russ likes to say, “If you haven’t found the tradeoffs, you’re not looking hard enough”. And as you might expect, there are tradeoffs when moving to a provider like Packet.
The biggest difference between Packet and the “big” clouds like AWS or GCP is that Packet just doesn’t have nearly the bells and whistles. Packet has just enough to provide some servers with basic networking and storage capabilities:
I personally think this simplicity is a net positive, but it does mean that when moving to such a provider, especially if you’re accustomed to the one-stop-shop that is GCP, Azure, or AWS, there are some things you’ll need to either implement yourself or find a third-party to provide.
As a point of emphasis, Antidote actually doesn’t need that much external “stuff”. Most of what Antidote needs is provided by Kubernetes - we really just need to get traffic to the cluster, and Kubernetes takes care of the rest. On top of that, we’re only running a single application - NRE Labs - on our cluster (in contrast to what most folks tend to do in the cloud). And even with all of these things going in our favor, we still had to account for three things that Packet doesn’t offer, that we had previously had as part of being in GCP.
This exercise made our deployment of NRE Labs a lot more portable. We don’t have plans to move from Packet any time soon, but in the event that we do decide to move in the future, having these components be implemented outside of the GCP umbrella means we only need to rip off that band-aid once.
1: Load Balancing to Cluster Nodes
Within the Kubernetes cluster that powers NRE Labs, we’re making use of the unofficial NGINX ingress controller for load balancing traffic to Pods. So within the cluster, we have load balancing taken care of. However, we still need to load-balance traffic to the cluster so that if one node dies, the other nodes will be used seamlessly.
When we were entirely in GCP, this was easy. Like all major cloud providers, there’s a built-in load-balancing service that offers basic reverse proxy and request routing functionality. However, when moving our cluster out of GCP, we ran into a catch that seems to be fairly prevalent across all the major cloud providers: those load balancing services only work for endpoints within those clouds. There was no way for us to continue to use the GCP load-balancing service, and point it to use our Packet servers as back-ends. So, once on Packet, we needed something that offered the same kind of fairly basic reverse-proxy functionality we had previously done with GCE’s built-in load balancer, but with the flexibility of being able to point to our Packet IPs.
We first considered DNS-based load balancing for this, since we didn’t need anything special - just needed to have an A record with all IP addresses for our worker nodes. However, if a server were to fail, this would blackhole the traffic that was destined to it, which pretty much defeated the purpose for us.
Since we also wanted to address some basic security needs at the same time, we settled on Cloudflare. In addition to the fact that it gave us what we wanted fairly cheaply (~10USD/mo), they also, like Packet, have a terraform provider. This meant that we could reference values retrieved from Packet resources, such as IP addresses, within Cloudflare resources, making it way easier to manage the infrastructure as a whole.
We also briefly looked at NS1 for a purely DNS-based solution but decided to stay with Cloudflare since we weren’t just planning to use Cloudflare for the load-balancing functionality, and the traditional HTTP-based health checks are good enough for us.
2: Basic Security Policies
With GCE, basic security/firewalling was a bit of a built-in. We set a security policy once, and every instance we spun up inherited this policy. Now that we’re on Packet, our servers are basically connected directly to the internet. This means we have to actually care a lot more about the firewall configuration on our servers.
So in addition to the Terraform definitions that we use to manage the infrastructure, our Ansible playbooks that continue configuring our cluster have been extended to include some basic iptables rules.
In addition to managing the on-server firewalls, Cloudflare provides a modicum of security by filtering out the really basic baddies.
3: Monitoring Cluster Utilization
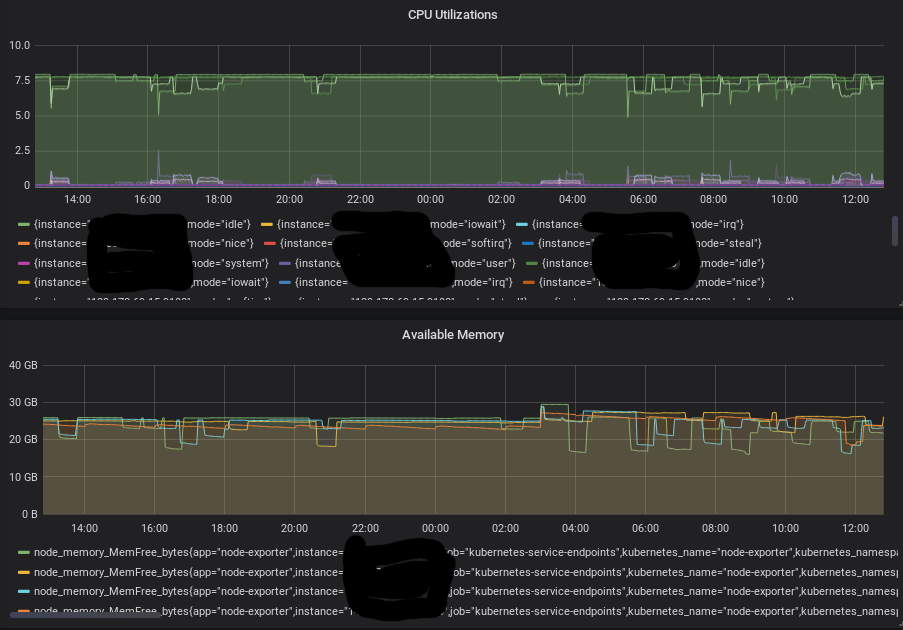
GCP, like other providers, includes basic monitoring offered as part of their service. I could see, for instance, the CPU utilization of my instances, to get a basic understanding of load at any given time. For memory utilization, we made use of separate service they offer called Stackdriver, which goes into way more detail. This ended up being pretty pricey, so we stopped using that, and started looking for alternatives.
It turned out that this was a timely initiative since when we moved out of GCP, none of the above was even an option anymore - we had to come up with our own solution for monitoring resource utilization. While there is more to monitoring than just looking at CPU and memory, and we certainly are continuing to add to our observability and monitoring toolbelt all the time, at a minimum, we wanted to know the CPU and RAM utilization across our cluster, since that was where the magic happened.
We eventually settled on Prometheus. Prometheus is well-integrated with Kubernetes, and the node exporter, which provides us what we were looking for in terms of per-node CPU and RAM utilization, deploys nicely as a DaemonSet in Kubernetes.
The screenshot near the top of this post was actually the graphs we set up to visualize the data in Prometheus that comes from the node exporter on each server:
Again, this was just for monitoring utilization on the cluster. This doesn’t get into anything observability-related, and it also doesn’t monitor anything outside of the Kubernetes cluster (we have a few instances still in GCP for various external functions). If you want holistic monitoring you may go with a more traditional monitoring solution.
Performance Gains
Now I would be remiss if I didn’t mention the performance improvements we have seen since moving to Packet. After all, since our cluster nodes are no longer virtual machines, and also since the per-core speed is much higher, we should be able to see a significant performance improvement, no?
Well, sure, probably. But the answer is actually a lot more nuanced. For the Antidote project, there are a number of factors that can heavily impact the time it takes to start an instance of a lesson:
- The software running in an Endpoint image
- The size of an Endpoint image, and how quickly it can be started from disk
- Endpoint configuration steps
So of course, cutting out a layer of virtualization and running on faster core speed should help significantly, but there are a lot of other places and ways to make lesson startups more efficient beyond “faster servers”, and we’re continuing to explore each path in parallel to improve the overall user experience.
That said, we started tracking lesson startup time fairly soon after we launched the project, so we could get a better understanding of how long users were having to wait from the time they initially start the lesson, to the point where they get a working terminal and lesson guide. Having this data, especially at a per-lesson granularity, and over time, is really helpful for understanding where we can make improvements.
We quickly noticed we had three classes of lesson startup times:
- Lessons with very simple endpoints (i.e. just a Linux container, no network devices) that started in under 20 seconds.
- Moderately complicated lessons with a few “heavy” endpoints like network devices. This the most common type of lesson in the curriculum currently. These would start anywhere between 80 to 100 seconds on average.
- Very complicated lessons with some kind of special software that needed to do something on startup in order to bootstrap itself (i.e. database queries). These usually take the longest to start, sometimes taking 5 minutes or more.

In this graph, the Y-axis represents lesson startup time in seconds.
In addition to these, the more complicated the lesson, the more diverse the “startup jitter”. Not only did they take longer to start, but their startup times were also even less predictable. Sometimes they would start in five minutes, but other times they would simply never start - often extending past Syringe’s default 30-minute garbage collection interval. As you may imagine, this is horrible user experience.
We switched the DNS records for NRE Labs over to our Packet cluster on August 10th, and we began to see not only a fairly dramatic reduction in startup times for lessons across the board (essentially cut in half) but the unpredictability we were seeing previously was almost nonexistent.
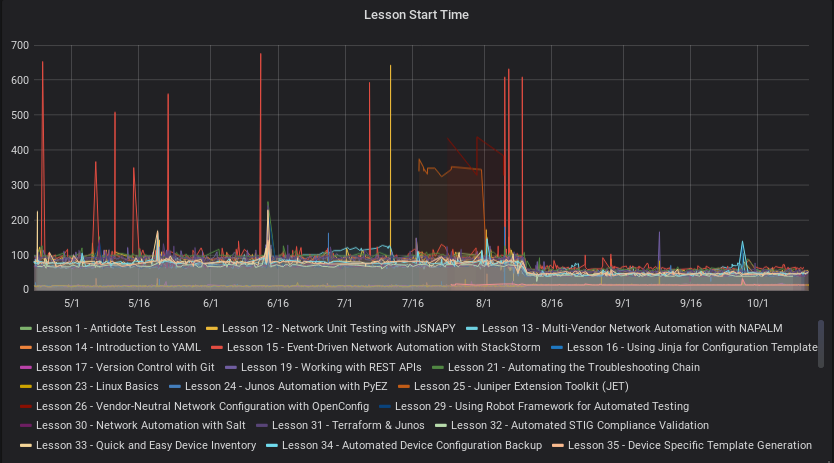
The very exciting bottom line: we’re able to start any lesson for our users, including complex lessons with fully on-demand read/write network devices, in under a minute, on average. This is not only a testament to the bare-metal performance shown here, but also the intentional design decisions around speed that we made when creating the Antidote platform.
Cost?
There’s always the question of cost when moving between providers, and this has come up a few times on Twitter as we publicly discussed the move while it was in-progress:
I remember that packet team are very good at creating joint marketing collateral. NRE example is a very interesting one, especially if the cost will be less than GCP's (or comparable). Would wait for the next posts about that migration ;)
— Roman Dodin (@ntdvps) August 13, 2019
Bottom line, the project is now spending generally less on compute resources for our Kubernetes cluster on Packet, but it’s not just a simple “this is cheaper than that” - there were a few factors that went into this, that should be taken to heart if you’re considering engaging with any compute provider of any kind:
- On-demand is EXPENSIVE no matter who you’re working with. Even if you’re just tinkering, go in with a gameplan to move from on-demand to at least a reserved model, if you intend to stay long-term. Some providers (including Packet) also have spot-pricing which is even cheaper, if your applications can live with this volatile model.
- The efficiency of well-sized compute resources cannot be understated. Spend the time to understand your application’s computing needs, and seek out the provider and the computing package that best fits this with as little overhead as possible. These providers allow you to create additional capacity very quickly, so try to avoid a bunch of unused computing resources for the “just in case” scenarios.
Together, these factors allowed us to get a much more cost-effective model in place for running the NRE Labs project.
Onward!
As of this writing, we’ve been on Packet for over two months, and things are still trekking along quite nicely. However, we’re always working on improving the back-end infrastructure and platform deployment for NRE Labs, in conjunction with improvements on the Antidote platform, and I look forward to seeing how this move sets us up for the next big success.